原文:
www.backtrader.com/
OCO 订单
原文:
www.backtrader.com/blog/posts/2017-03-19-oco/oco/
版本 1.9.34.116 添加了OCO(又称一次取消其他)到回测工具中。
注意
这只在回测中实现,尚未实现对实时经纪商的实现
注意
与版本 1.9.36.116 更新。交互式经纪商支持StopTrail,StopTrailLimit和OCO。
-
OCO始终指定组中的第一个订单作为参数oco -
StopTrailLimit:经纪商模拟和IB经纪商具有相同的行为。指定:price作为初始停止触发价格(还要指定trailamount),然后将plimi指定为初始限价。两者之间的差异将确定limitoffset(限价与停止触发价格之间的距离)
使用模式尝试保持用户友好。因此,如果策略中的逻辑决定发出订单的时机,可以像这样使用OCO:
def next(self):
...
o1 = self.buy(...)
...
o2 = self.buy(..., oco=o1)
...
o3 = self.buy(..., oco=o1) # or even oco=o2, o2 is already in o1 group
简单。第一个订单o1将成为组的领导者。通过指定带有名为oco的参数的o1,o2和o3将成为OCO 组的一部分。请注意,片段中的注释指出o3也可以通过指定o2(已成为组的一部分)成为组的一部分
当形成组时,将会发生以下情况:
- 如果组中的任何订单被执行、取消或到期,其他订单将被取消。
下面的示例展示了OCO概念的应用。带有图表的标准执行:
$ ./oco.py --broker cash=50000 --plot
注意
现金增加到50000,因为资产达到4000的价值,而且 3 个1个项目的订单至少需要12000货币单位(经纪人的默认值为10000)
随着下图发生。
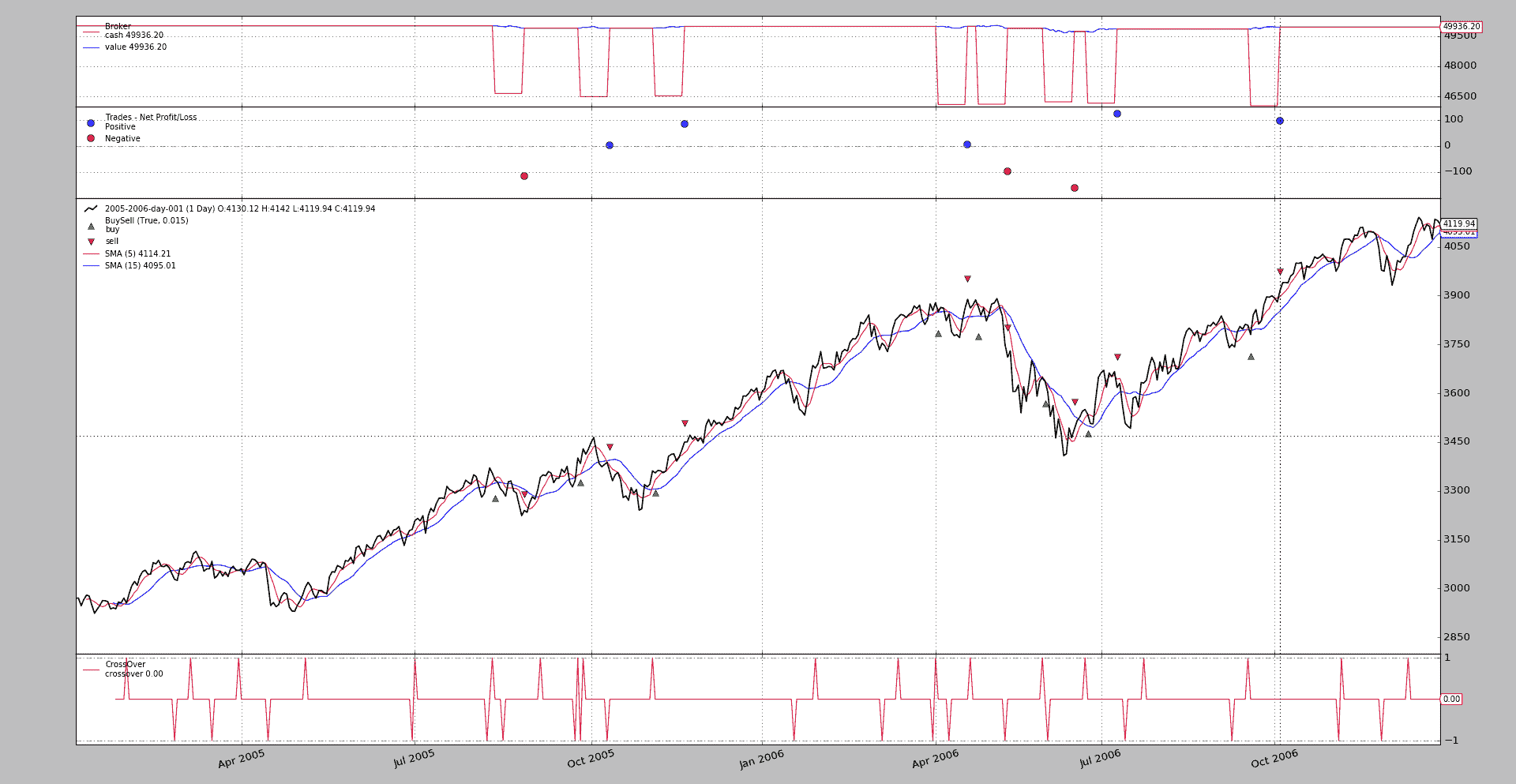
实际上这并没有提供太多信息(这是一个标准的SMA 交叉策略)。该示例执行以下操作:
-
当快速 SMA 向上穿过慢速 SMA 时,将发出 3 个订单
-
order1是一个将在limdays天内到期的Limit订单,限价为关闭价格减少的百分比 -
order2是一个具有更长到期时间和更低限价的Limit订单。 -
order3是一个进一步降低限价的Limit订单
因此,order2 和 order3 的执行将不会发生,因为:
order1将首先被执行,这应该触发其他订单的取消
或者
order1将过期,这将触发其他订单的取消
系统保留 3 个订单的ref标识符,并且只有在notify_order中看到三个ref标识符被视为Completed,Cancelled,Margin或Expired时,才会发出新的buy订单
在持有仓位一段时间后退出。
为了尝试跟踪实际执行情况,生成文本输出。其中一些内容:
2005-01-28: Oref 1 / Buy at 2941.11055
2005-01-28: Oref 2 / Buy at 2896.7722
2005-01-28: Oref 3 / Buy at 2822.87495
2005-01-31: Order ref: 1 / Type Buy / Status Submitted
2005-01-31: Order ref: 2 / Type Buy / Status Submitted
2005-01-31: Order ref: 3 / Type Buy / Status Submitted
2005-01-31: Order ref: 1 / Type Buy / Status Accepted
2005-01-31: Order ref: 2 / Type Buy / Status Accepted
2005-01-31: Order ref: 3 / Type Buy / Status Accepted
2005-02-01: Order ref: 1 / Type Buy / Status Expired
2005-02-01: Order ref: 3 / Type Buy / Status Canceled
2005-02-01: Order ref: 2 / Type Buy / Status Canceled
...
2006-06-23: Oref 49 / Buy at 3532.39925
2006-06-23: Oref 50 / Buy at 3479.147
2006-06-23: Oref 51 / Buy at 3390.39325
2006-06-26: Order ref: 49 / Type Buy / Status Submitted
2006-06-26: Order ref: 50 / Type Buy / Status Submitted
2006-06-26: Order ref: 51 / Type Buy / Status Submitted
2006-06-26: Order ref: 49 / Type Buy / Status Accepted
2006-06-26: Order ref: 50 / Type Buy / Status Accepted
2006-06-26: Order ref: 51 / Type Buy / Status Accepted
2006-06-26: Order ref: 49 / Type Buy / Status Completed
2006-06-26: Order ref: 51 / Type Buy / Status Canceled
2006-06-26: Order ref: 50 / Type Buy / Status Canceled
...
2006-11-10: Order ref: 61 / Type Buy / Status Canceled
2006-12-11: Oref 63 / Buy at 4032.62555
2006-12-11: Oref 64 / Buy at 3971.8322
2006-12-11: Oref 65 / Buy at 3870.50995
2006-12-12: Order ref: 63 / Type Buy / Status Submitted
2006-12-12: Order ref: 64 / Type Buy / Status Submitted
2006-12-12: Order ref: 65 / Type Buy / Status Submitted
2006-12-12: Order ref: 63 / Type Buy / Status Accepted
2006-12-12: Order ref: 64 / Type Buy / Status Accepted
2006-12-12: Order ref: 65 / Type Buy / Status Accepted
2006-12-15: Order ref: 63 / Type Buy / Status Expired
2006-12-15: Order ref: 65 / Type Buy / Status Canceled
2006-12-15: Order ref: 64 / Type Buy / Status Canceled
随着以下事件发生:
-
第一批订单已发布。订单 1 到期,2 和 3 被取消。如预期的那样。
-
几个月后,另一批包含 3 个订单的订单被发布。在这种情况下,订单 49 被标记为
已完成,而 50 和 51 立即被取消。 -
最后一批就像第一批一样
现在让我们来检查一下没有 OCO 的行为:
$ ./oco.py --strat do_oco=False --broker cash=50000
2005-01-28: Oref 1 / Buy at 2941.11055
2005-01-28: Oref 2 / Buy at 2896.7722
2005-01-28: Oref 3 / Buy at 2822.87495
2005-01-31: Order ref: 1 / Type Buy / Status Submitted
2005-01-31: Order ref: 2 / Type Buy / Status Submitted
2005-01-31: Order ref: 3 / Type Buy / Status Submitted
2005-01-31: Order ref: 1 / Type Buy / Status Accepted
2005-01-31: Order ref: 2 / Type Buy / Status Accepted
2005-01-31: Order ref: 3 / Type Buy / Status Accepted
2005-02-01: Order ref: 1 / Type Buy / Status Expired
就是这样,没有什么(没有订单执行,对图表的需求也不大)
-
订单批次已发布
-
订单 1 到期了,但因为策略已经设置了参数
do_oco=False,订单 2 和 3 没有成为OCO组的一部分。 -
因此,订单 2 和 3 并没有被取消,并且由于默认到期天数是
1000天,根据样本的可用数据(2 年数据),它们永远不会到期。 -
系统从未发布过第二批订单。
示例用法
$ ./oco.py --help
usage: oco.py [-h] [--data0 DATA0] [--fromdate FROMDATE] [--todate TODATE]
[--cerebro kwargs] [--broker kwargs] [--sizer kwargs]
[--strat kwargs] [--plot [kwargs]]
Sample Skeleton
optional arguments:
-h, --help show this help message and exit
--data0 DATA0 Data to read in (default:
../../datas/2005-2006-day-001.txt)
--fromdate FROMDATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default: )
--todate TODATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default: )
--cerebro kwargs kwargs in key=value format (default: )
--broker kwargs kwargs in key=value format (default: )
--sizer kwargs kwargs in key=value format (default: )
--strat kwargs kwargs in key=value format (default: )
--plot [kwargs] kwargs in key=value format (default: )
示例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import backtrader as bt
class St(bt.Strategy):
params = dict(
ma=bt.ind.SMA,
p1=5,
p2=15,
limit=0.005,
limdays=3,
limdays2=1000,
hold=10,
switchp1p2=False, # switch prices of order1 and order2
oco1oco2=False, # False - use order1 as oco for order3, else order2
do_oco=True, # use oco or not
)
def notify_order(self, order):
print('{}: Order ref: {} / Type {} / Status {}'.format(
self.data.datetime.date(0),
order.ref, 'Buy' * order.isbuy() or 'Sell',
order.getstatusname()))
if order.status == order.Completed:
self.holdstart = len(self)
if not order.alive() and order.ref in self.orefs:
self.orefs.remove(order.ref)
def __init__(self):
ma1, ma2 = self.p.ma(period=self.p.p1), self.p.ma(period=self.p.p2)
self.cross = bt.ind.CrossOver(ma1, ma2)
self.orefs = list()
def next(self):
if self.orefs:
return # pending orders do nothing
if not self.position:
if self.cross > 0.0: # crossing up
p1 = self.data.close[0] * (1.0 - self.p.limit)
p2 = self.data.close[0] * (1.0 - 2 * 2 * self.p.limit)
p3 = self.data.close[0] * (1.0 - 3 * 3 * self.p.limit)
if self.p.switchp1p2:
p1, p2 = p2, p1
o1 = self.buy(exectype=bt.Order.Limit, price=p1,
valid=datetime.timedelta(self.p.limdays))
print('{}: Oref {} / Buy at {}'.format(
self.datetime.date(), o1.ref, p1))
oco2 = o1 if self.p.do_oco else None
o2 = self.buy(exectype=bt.Order.Limit, price=p2,
valid=datetime.timedelta(self.p.limdays2),
oco=oco2)
print('{}: Oref {} / Buy at {}'.format(
self.datetime.date(), o2.ref, p2))
if self.p.do_oco:
oco3 = o1 if not self.p.oco1oco2 else oco2
else:
oco3 = None
o3 = self.buy(exectype=bt.Order.Limit, price=p3,
valid=datetime.timedelta(self.p.limdays2),
oco=oco3)
print('{}: Oref {} / Buy at {}'.format(
self.datetime.date(), o3.ref, p3))
self.orefs = [o1.ref, o2.ref, o3.ref]
else: # in the market
if (len(self) - self.holdstart) >= self.p.hold:
self.close()
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
kwargs = dict()
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
for a, d in ((getattr(args, x), x) for x in ['fromdate', 'todate']):
if a:
strpfmt = dtfmt + tmfmt * ('T' in a)
kwargs[d] = datetime.datetime.strptime(a, strpfmt)
# Data feed
data0 = bt.feeds.BacktraderCSVData(dataname=args.data0, **kwargs)
cerebro.adddata(data0)
# Broker
cerebro.broker = bt.brokers.BackBroker(**eval('dict(' + args.broker + ')'))
# Sizer
cerebro.addsizer(bt.sizers.FixedSize, **eval('dict(' + args.sizer + ')'))
# Strategy
cerebro.addstrategy(St, **eval('dict(' + args.strat + ')'))
# Execute
cerebro.run(**eval('dict(' + args.cerebro + ')'))
if args.plot: # Plot if requested to
cerebro.plot(**eval('dict(' + args.plot + ')'))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=(
'Sample Skeleton'
)
)
parser.add_argument('--data0', default='../../datas/2005-2006-day-001.txt',
required=False, help='Data to read in')
# Defaults for dates
parser.add_argument('--fromdate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--todate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--cerebro', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--broker', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--sizer', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--strat', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--plot', required=False, default='',
nargs='?', const='{}',
metavar='kwargs', help='kwargs in key=value format')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()
在同一轴上绘图
原文:
www.backtrader.com/blog/posts/2017-03-17-plot-sameaxis/plot-sameaxis/
以前的帖子《期货和现货补偿》在相同空间上绘制了原始数据和略微(随机)修改的数据,但没有在相同轴上绘制。
从该帖子中恢复第 1 张图片。
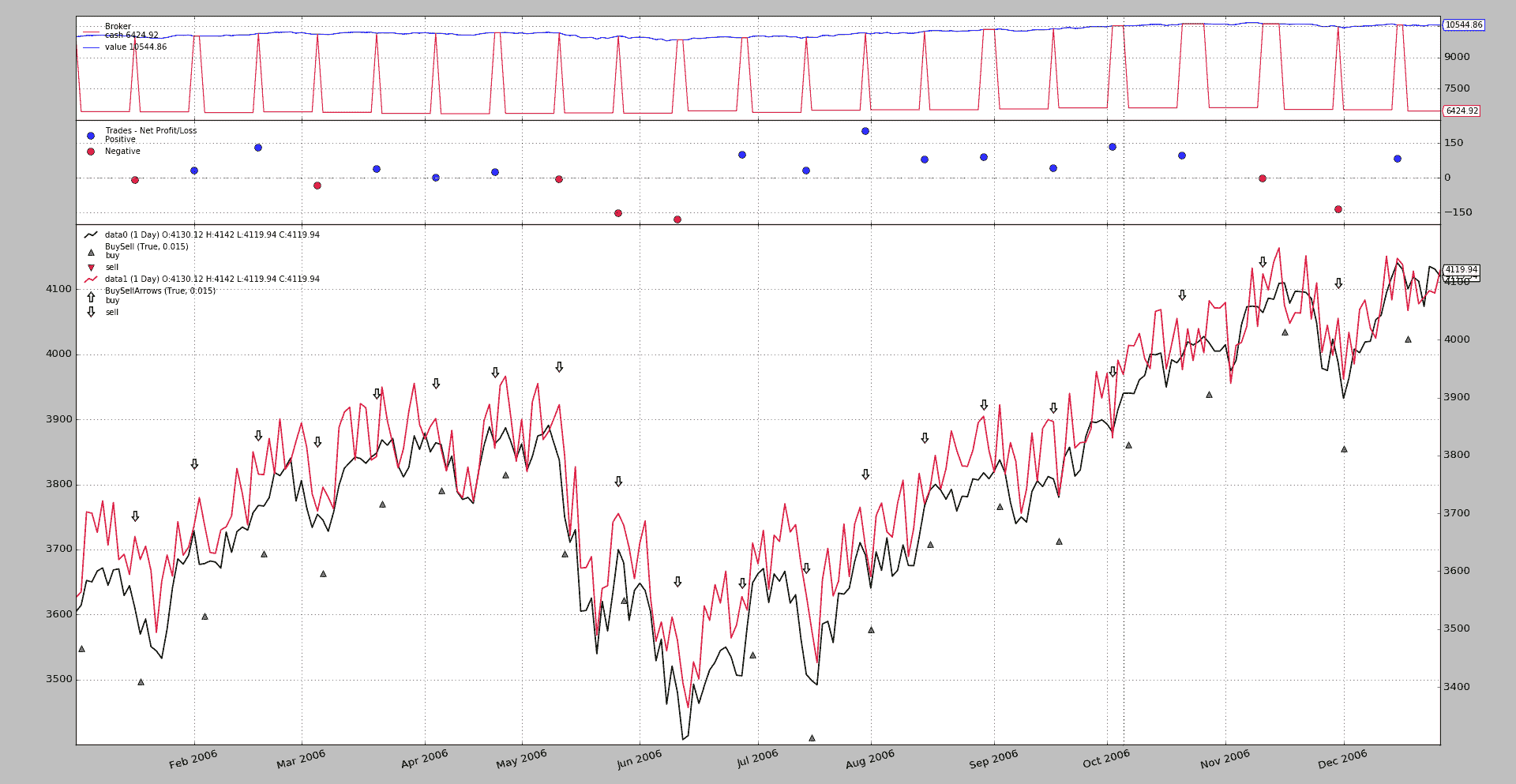
人们可以看到:
-
图表的左右两侧有不同的刻度
-
当看摆动的红线(随机数据)时,这一点最为明显,它在原始数据周围振荡
+- 50点。在图表上,视觉印象是这些随机数据大多总是在原始数据之上。这只是由于不同的比例而产生的视觉印象。
尽管发布版本1.9.32.116已经初步支持在同一轴上进行完整绘制,但是图例标签将被复制(仅标签,不是数据),这真的很令人困惑。
发布版本1.9.33.116修复了该问题,并允许在同一轴上进行完整绘图。使用模式类似于决定与哪些其他数据一起绘制。来自上一篇帖子。
import backtrader as bt
cerebro = bt.Cerebro()
data0 = bt.feeds.MyFavouriteDataFeed(dataname='futurename')
cerebro.adddata(data0)
data1 = bt.feeds.MyFavouriteDataFeed(dataname='spotname')
data1.compensate(data0) # let the system know ops on data1 affect data0
data1.plotinfo.plotmaster = data0
data1.plotinfo.sameaxis = True
cerebro.adddata(data1)
...
cerebro.run()
data1得到一些plotinfo值以:
-
在与
plotmaster(即data0)相同的空间上绘图 -
获取使用
sameaxis的指示这一指示的原因是平台无法预先知道每个数据的刻度是否兼容。这就是为什么它会在独立的刻度上绘制它们的原因。
前面的示例获得了一个额外选项来在sameaxis上绘制。一个示例执行:
$ ./future-spot.py --sameaxis
结果图表
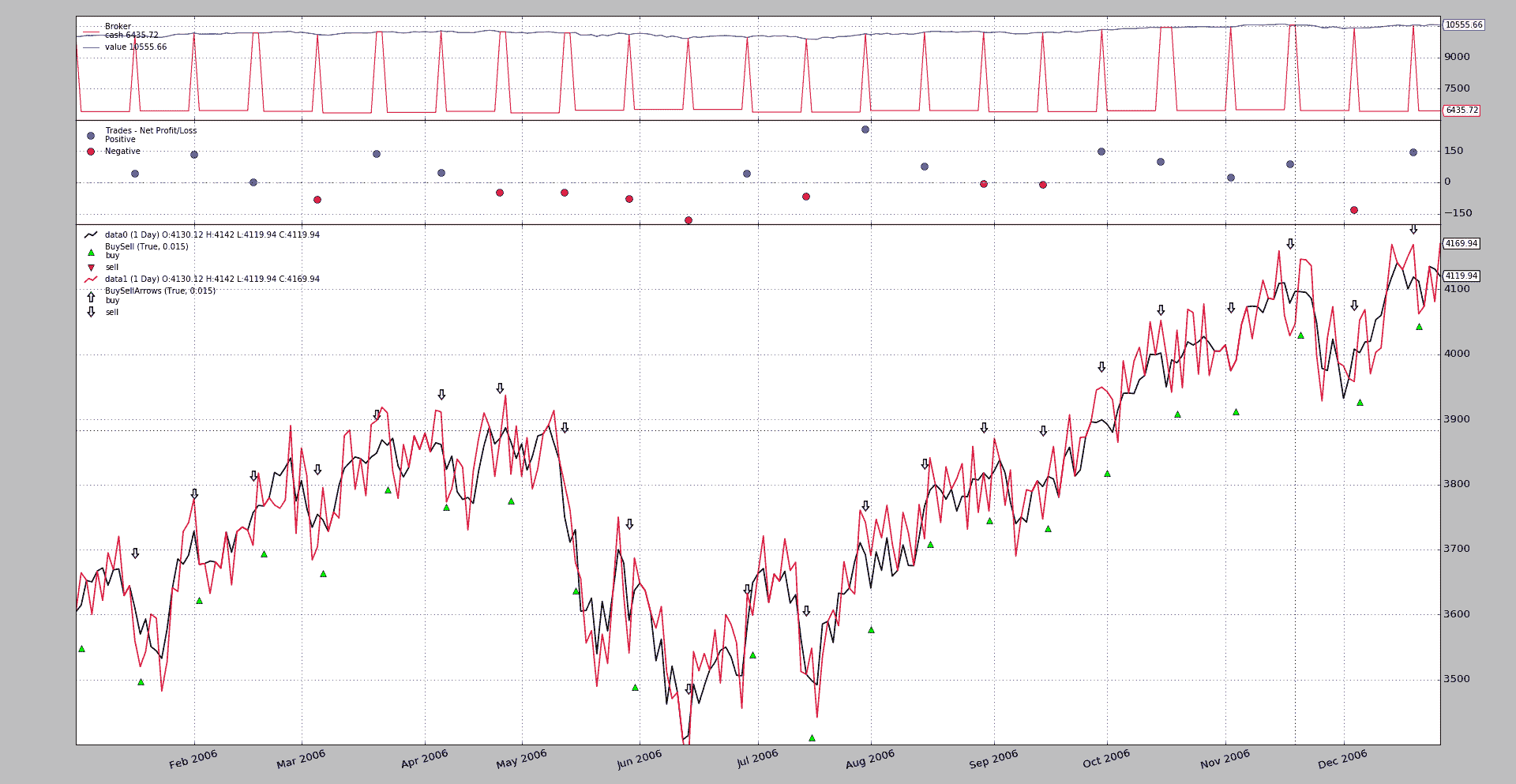
注意:
-
右侧只有一个刻度
-
现在,随机化数据似乎清楚地在原始数据周围振荡,这是预期的可视行为
示例用法
$ ./future-spot.py --help
usage: future-spot.py [-h] [--no-comp] [--sameaxis]
Compensation example
optional arguments:
-h, --help show this help message and exit
--no-comp
--sameaxis
示例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import random
import backtrader as bt
# The filter which changes the close price
def close_changer(data, *args, **kwargs):
data.close[0] += 50.0 * random.randint(-1, 1)
return False # length of stream is unchanged
# override the standard markers
class BuySellArrows(bt.observers.BuySell):
plotlines = dict(buy=dict(marker='$\u21E7$', markersize=12.0),
sell=dict(marker='$\u21E9$', markersize=12.0))
class St(bt.Strategy):
def __init__(self):
bt.obs.BuySell(self.data0, barplot=True) # done here for
BuySellArrows(self.data1, barplot=True) # different markers per data
def next(self):
if not self.position:
if random.randint(0, 1):
self.buy(data=self.data0)
self.entered = len(self)
else: # in the market
if (len(self) - self.entered) >= 10:
self.sell(data=self.data1)
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
dataname = '../../datas/2006-day-001.txt' # data feed
data0 = bt.feeds.BacktraderCSVData(dataname=dataname, name='data0')
cerebro.adddata(data0)
data1 = bt.feeds.BacktraderCSVData(dataname=dataname, name='data1')
data1.addfilter(close_changer)
if not args.no_comp:
data1.compensate(data0)
data1.plotinfo.plotmaster = data0
if args.sameaxis:
data1.plotinfo.sameaxis = True
cerebro.adddata(data1)
cerebro.addstrategy(St) # sample strategy
cerebro.addobserver(bt.obs.Broker) # removed below with stdstats=False
cerebro.addobserver(bt.obs.Trades) # removed below with stdstats=False
cerebro.broker.set_coc(True)
cerebro.run(stdstats=False) # execute
cerebro.plot(volume=False) # and plot
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=('Compensation example'))
parser.add_argument('--no-comp', required=False, action='store_true')
parser.add_argument('--sameaxis', required=False, action='store_true')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()
期货和现货补偿
原文:
www.backtrader.com/blog/posts/2017-03-15-future-vs-spot/future-vs-spot/
发布1.9.32.116添加了对社区中提出的一个有趣用例的支持
-
使用期货开始交易,其中包括实物交付
-
让指标告诉你一些信息
-
如果需要,通过操作现货价格来关闭持仓,从而有效地取消实物交付,无论是为了收到货物还是为了交付货物(并希望获利)。
期货在同一天到期,与现货价格的操作同时进行。
这意味着:
-
平台接收来自两种不同资产的数据点
-
平台必须以某种方式理解资产之间的关联,并且现货价格的操作将关闭期货的持仓。
实际上,期货并没有关闭,只是实物交付被补偿了。
使用补偿概念,backtrader添加了一种让用户与平台通信的方式,即一个数据源上的事物会对另一个数据源产生补偿效果。 使用模式
import backtrader as bt
cerebro = bt.Cerebro()
data0 = bt.feeds.MyFavouriteDataFeed(dataname='futurename')
cerebro.adddata(data0)
data1 = bt.feeds.MyFavouriteDataFeed(dataname='spotname')
data1.compensate(data0) # let the system know ops on data1 affect data0
cerebro.adddata(data1)
...
cerebro.run()
将所有内容放在一起
一个例子总比千言万语更有说服力,所以让我们把所有的要点都放在一起。
-
使用
backtrader源中的标准样本数据源之一。 这将是期货。 -
通过重新使用相同的数据源并添加一个过滤器来模拟类似但不同的价格,该过滤器将随机将价格上/下移动一些点,以创建价差。 就像这样简单:
# The filter which changes the close price def close_changer(data, *args, **kwargs): data.close[0] += 50.0 * random.randint(-1, 1) return False # length of stream is unchanged` -
在同一轴上绘制将混合默认包含的
BuyObserver标记,因此标准观察者将被禁用,并手动重新添加以使用不同的每个数据标记进行绘制 -
位置将随机进入并在 10 天后退出。
这与期货到期期间不匹配,但这只是为了将功能放在那里,而不是检查交易日历
!!! 注意
A simulation including execution on the spot price on the day of
future expiration would require activating `cheat-on-close` to
make sure the orders are executed when the future expires. This is
not needed in this sample, because the expiration is being chosen
at random.
-
注意策略
-
buy操作在data0上执行 -
sell操作在data1上执行
class St(bt.Strategy): def __init__(self): bt.obs.BuySell(self.data0, barplot=True) # done here for BuySellArrows(self.data1, barplot=True) # different markers per data def next(self): if not self.position: if random.randint(0, 1): self.buy(data=self.data0) self.entered = len(self) else: # in the market if (len(self) - self.entered) >= 10: self.sell(data=self.data1)` -
执行:
$ ./future-spot.py --no-comp
使用这个图形输出。
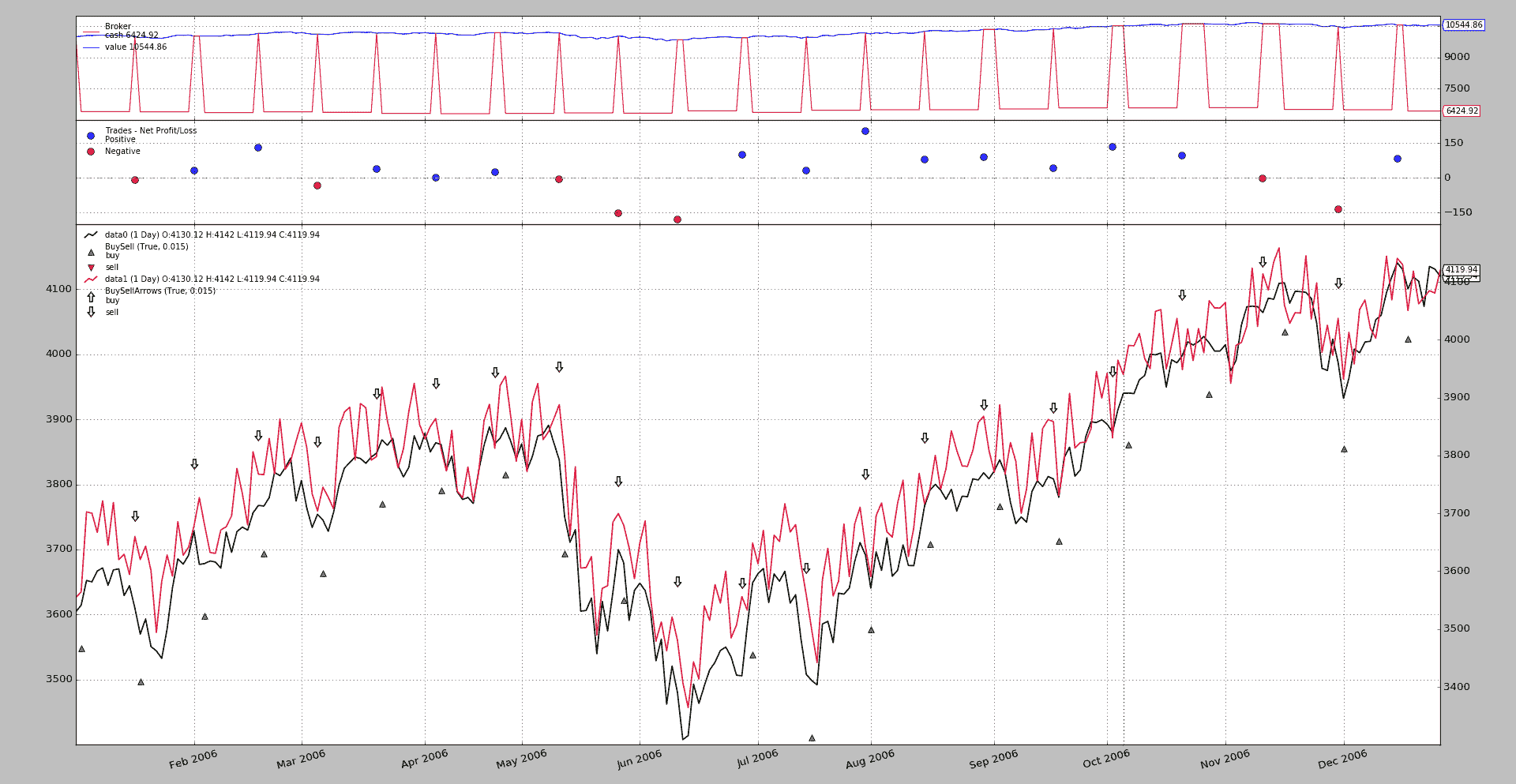
它有效:
-
buy操作以绿色向上指的三角形表示,图例告诉我们它们属于data0,正如预期的那样。 -
sell操作通过向下指的箭头表示,图例告诉我们它们属于data1,正如预期的那样。 -
交易正在关闭,即使它们是在
data0上开启的,并且是在data1上关闭的,也能达到期望的效果(在现实生活中,这意味着避免通过期货获得的货物的实际交付)。
只能想象如果应用相同的逻辑而不进行补偿会发生什么。 让我们试试:
$ ./future-spot.py --no-comp
和输出
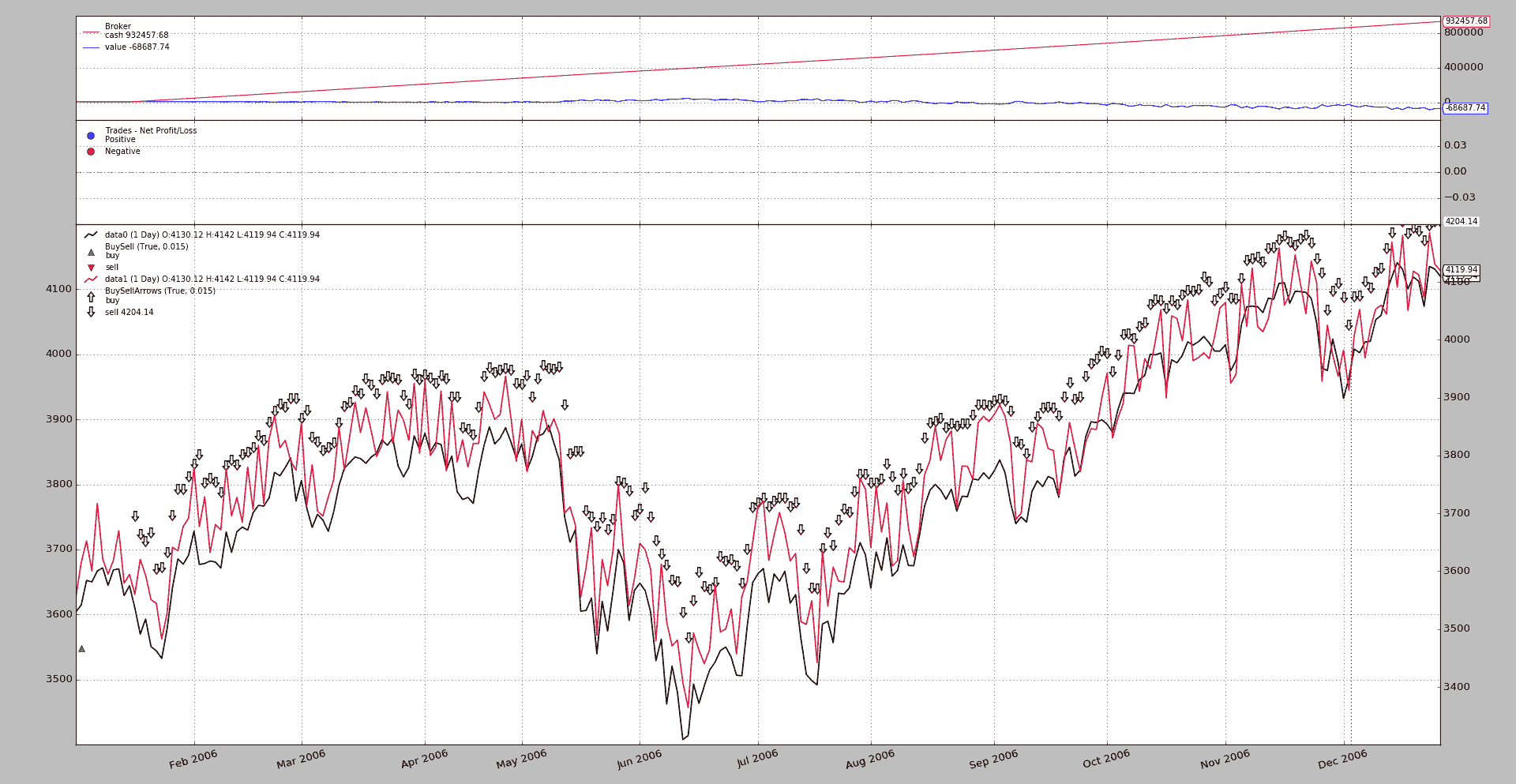
这显然是失败的:
-
逻辑期望在
data0上的位置在对data1的操作关闭时关闭,并且仅当不在市场上时才打开data0上的位置。 -
但是补偿已被停用,并且对
data0的初始操作(绿色三角形)从未关闭,因此不会启动任何其他操作,而data1上的空头头寸开始积累。
示例用法
$ ./future-spot.py --help
usage: future-spot.py [-h] [--no-comp]
Compensation example
optional arguments:
-h, --help show this help message and exit
--no-comp
示例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import random
import backtrader as bt
# The filter which changes the close price
def close_changer(data, *args, **kwargs):
data.close[0] += 50.0 * random.randint(-1, 1)
return False # length of stream is unchanged
# override the standard markers
class BuySellArrows(bt.observers.BuySell):
plotlines = dict(buy=dict(marker='$\u21E7$', markersize=12.0),
sell=dict(marker='$\u21E9$', markersize=12.0))
class St(bt.Strategy):
def __init__(self):
bt.obs.BuySell(self.data0, barplot=True) # done here for
BuySellArrows(self.data1, barplot=True) # different markers per data
def next(self):
if not self.position:
if random.randint(0, 1):
self.buy(data=self.data0)
self.entered = len(self)
else: # in the market
if (len(self) - self.entered) >= 10:
self.sell(data=self.data1)
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
dataname = '../../datas/2006-day-001.txt' # data feed
data0 = bt.feeds.BacktraderCSVData(dataname=dataname, name='data0')
cerebro.adddata(data0)
data1 = bt.feeds.BacktraderCSVData(dataname=dataname, name='data1')
data1.addfilter(close_changer)
if not args.no_comp:
data1.compensate(data0)
data1.plotinfo.plotmaster = data0
cerebro.adddata(data1)
cerebro.addstrategy(St) # sample strategy
cerebro.addobserver(bt.obs.Broker) # removed below with stdstats=False
cerebro.addobserver(bt.obs.Trades) # removed below with stdstats=False
cerebro.broker.set_coc(True)
cerebro.run(stdstats=False) # execute
cerebro.plot(volume=False) # and plot
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=('Compensation example'))
parser.add_argument('--no-comp', required=False, action='store_true')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()
绘制日期范围
原文:
www.backtrader.com/blog/posts/2017-03-07-plotting-date-ranges/plotting-date-ranges/
发布 1.9.31.x 添加了制作部分图形的功能。
-
要么使用完整长度数组的索引来获取 strategy 实例中保存的 timestamps
-
或者使用实际的
datetime.date或datetime.datetime实例,限制需要绘制的内容。
一切仍然在标准的 cerebro.plot 之上。例如:
cerebro.plot(start=datetime.date(2005, 7, 1), end=datetime.date(2006, 1, 31))
对于人类而言,这是一种直接的方法。具有扩展功能的人类实际上可以尝试将索引映射到 datetime 时间戳,如下所示:
cerebro.plot(start=75, end=185)
一个非常标准的示例包含了 简单移动平均(在数据绘图中)、随机指标(独立绘图)和 随机指标 线的 交叉,如下所示。cerebro.plot 的参数作为命令行参数传递。
使用 date 方法进行执行:
./partial-plot.py --plot 'start=datetime.date(2005, 7, 1),end=datetime.date(2006, 1, 31)'
Python 中的 eval 魔法允许在命令行中直接编写 datetime.date 并将其实际映射到合理的内容。输出图表
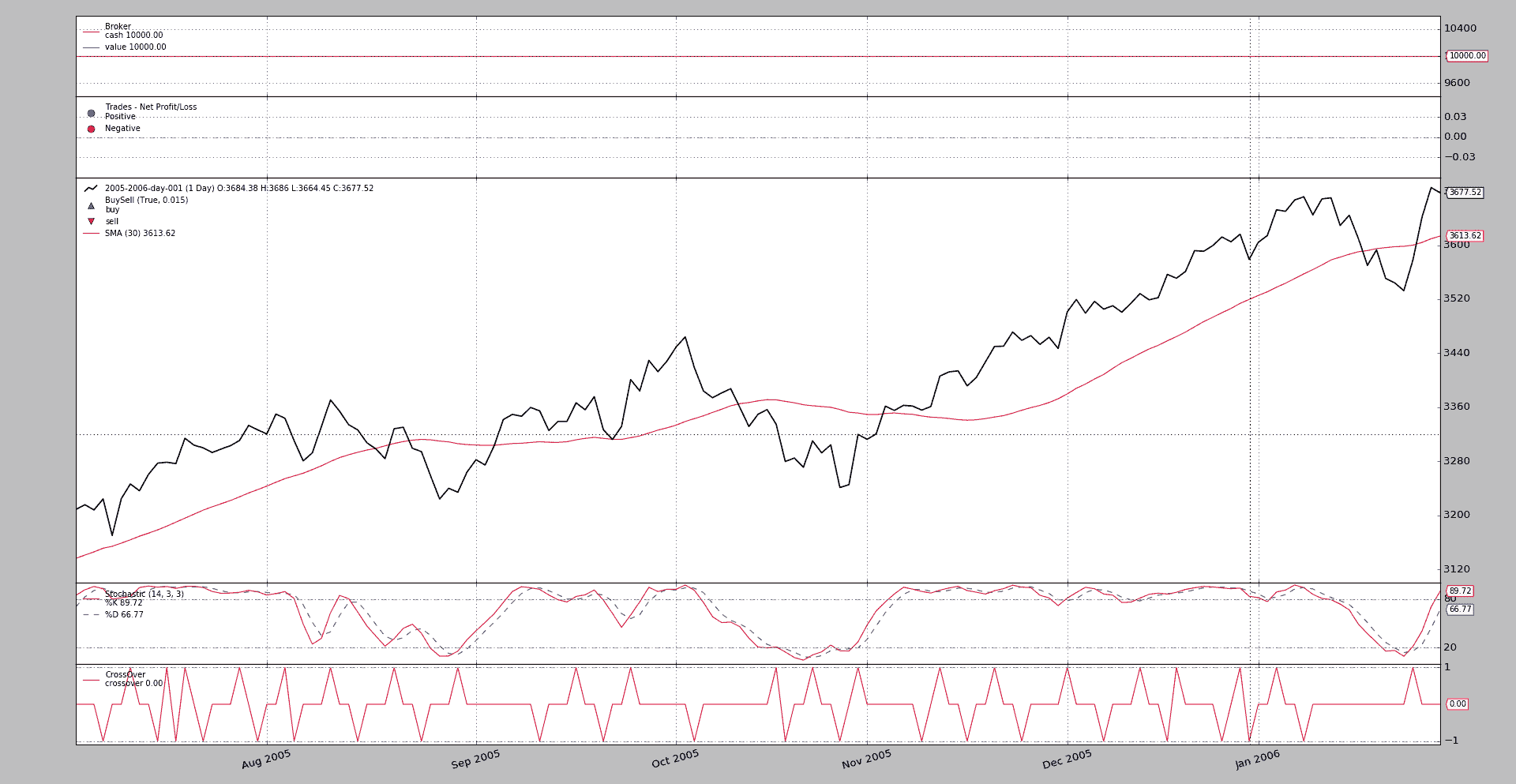
让我们与完整的图形进行比较,看看数据实际上是从两端跳过的:
./partial-plot.py --plot
Python 中的 eval 魔法允许在命令行中直接编写 datetime.date 并将其实际映射到合理的内容。输出图表
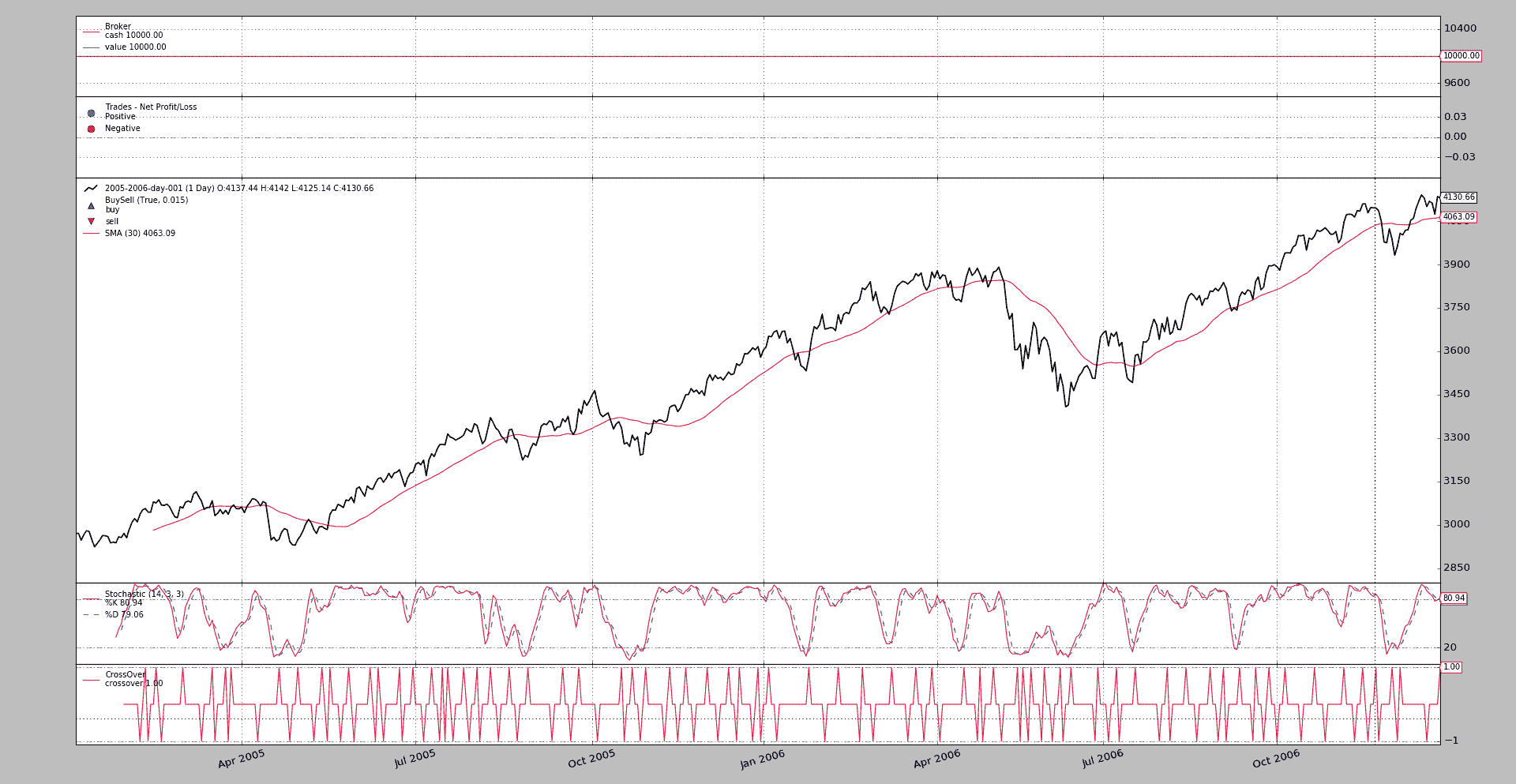
示例用法
$ ./partial-plot.py --help
usage: partial-plot.py [-h] [--data0 DATA0] [--fromdate FROMDATE]
[--todate TODATE] [--cerebro kwargs] [--broker kwargs]
[--sizer kwargs] [--strat kwargs] [--plot [kwargs]]
Sample for partial plotting
optional arguments:
-h, --help show this help message and exit
--data0 DATA0 Data to read in (default:
../../datas/2005-2006-day-001.txt)
--fromdate FROMDATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default: )
--todate TODATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default: )
--cerebro kwargs kwargs in key=value format (default: )
--broker kwargs kwargs in key=value format (default: )
--sizer kwargs kwargs in key=value format (default: )
--strat kwargs kwargs in key=value format (default: )
--plot [kwargs] kwargs in key=value format (default: )
代码示例
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import backtrader as bt
class St(bt.Strategy):
params = (
)
def __init__(self):
bt.ind.SMA()
stoc = bt.ind.Stochastic()
bt.ind.CrossOver(stoc.lines.percK, stoc.lines.percD)
def next(self):
pass
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
kwargs = dict()
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
for a, d in ((getattr(args, x), x) for x in ['fromdate', 'todate']):
if a:
strpfmt = dtfmt + tmfmt * ('T' in a)
kwargs[d] = datetime.datetime.strptime(a, strpfmt)
# Data feed
data0 = bt.feeds.BacktraderCSVData(dataname=args.data0, **kwargs)
cerebro.adddata(data0)
# Broker
cerebro.broker = bt.brokers.BackBroker(**eval('dict(' + args.broker + ')'))
# Sizer
cerebro.addsizer(bt.sizers.FixedSize, **eval('dict(' + args.sizer + ')'))
# Strategy
cerebro.addstrategy(St, **eval('dict(' + args.strat + ')'))
# Execute
cerebro.run(**eval('dict(' + args.cerebro + ')'))
if args.plot: # Plot if requested to
cerebro.plot(**eval('dict(' + args.plot + ')'))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=(
'Sample for partial plotting'
)
)
parser.add_argument('--data0', default='../../datas/2005-2006-day-001.txt',
required=False, help='Data to read in')
# Defaults for dates
parser.add_argument('--fromdate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--todate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--cerebro', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--broker', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--sizer', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--strat', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--plot', required=False, default='',
nargs='?', const='{}',
metavar='kwargs', help='kwargs in key=value format')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()
卡尔曼等人
原文:
www.backtrader.com/blog/posts/2017-02-14-kalman-et-al/kalman-et-al/
注
下面指令的支持始于提交
在开发分支中的 1146c83d9f9832630e97daab3ec7359705dc2c77
发布版本 1.9.30.x 将是第 1 个包含它的版本。
backtrader 的一个最初目标是保持纯 Python,即:只使用标准发行版中可用的包。与 matplotlib 一起做了一个例外,以便在不重新发明轮子的情况下进行绘图。尽管在最后可能的时刻导入以避免干扰可能根本不需要绘图的标准操作(并避免如果没有安装和不希望绘图时出现错误)
第 2 个例外部分地使用了 pytz,当添加对可能位于本地时区之外的实时数据源的时区支持时。同样,import 操作在后台进行,仅在 pytz 可用时才进行(用户可以选择传递 pytz 实例)
但现在是时候做一个完全的例外了,因为 backtraders 使用着像 numpy、pandas、statsmodel 这样的著名包,以及一些更谦逊的包,比如 pykalman。否则,将这些包使用到平台中。
社区中的一些示例:
-
移植一个依赖于 pandas dataframe 的指标
-
线性回归和标准差 #211
-
机器学习 + backtrader
这个愿望已经添加到这里简要规划的快速路线图中:
- v1.x - 快速路线图
声明式方法
保持 backtrader 的原始精神,并同时允许使用这些包的关键是不强制纯 Python 用户必须安装这些包。
虽然这可能看起来具有挑战性并且容易出现多个条件语句,但在平台内部和外部用户方面,这种方法都是依赖于已用于开发其他概念的相同原则,例如 参数(称为 params)。
让我们回顾一下如何定义接受 params 并定义 lines 的 Indicator:
class MyIndicator(bt.Indicator):
lines = ('myline',)
params = (
('period', 50),
)
以及后续可以作为 self.params.period 或 self.p.period 的参数:
def __init__(self):
print('my period is:', self.p.period)
以及作为 self.lines.myline 或 self.l.myline 的当前值:
def next(self):
print('mylines[0]:', self.lines.myline[0])
这并不特别有用,只是展示了 声明式 方法的 params 背景机制,该机制还具有适当的继承支持(包括 多继承)
引入 packages
使用相同的声明技术(有些人称之为 元编程),支持外部 包 可以这样实现:
class MyIndicator(bt.Indicator):
packages = ('pandas',)
lines = ('myline',)
params = (
('period', 50),
)
天啊!这似乎只是另一个声明。指标的实施者的第一个问题将是:
- 我需要手动导入
pandas吗?
答案很明显:不。后台机制将导入 pandas 并使其在定义 MyIndicator 的模块中可用。现在可以在 next 中执行以下操作:
def next(self):
print('mylines[0]:', pandas.SomeFunction(self.lines.myline[0]))
packages 指令也可以用于:
-
在一个声明中导入多个包
-
将导入分配给别名,如
import pandas as pd
假设还希望将 statsmodel 命名为 sm 以完成 pandas.SomeFunction:
class MyIndicator(bt.Indicator):
packages = ('pandas', ('statsmodel', 'sm'),)
lines = ('myline',)
params = (
('period', 50),
)
def next(self):
print('mylines[0]:', sm.XX(pandas.SomeFunction(self.lines.myline[0])))
statsmodel 已被导入为 sm 并可用。只需传递一个可迭代对象(tuple 是 backtrader 的约定)包含包的名称和所需的别名。
添加 frompackages
Python 以不断查找事物而闻名,这也是该语言在动态性、内省设施和元编程方面出色的原因之一。同时也是无法提供相同性能的原因之一。
常见的加速之一是通过直接从模块中导入符号而不是查找模块来实现本地查找。使用我们从 pandas 中的 SomeFunction,会是这样的:
from pandas import SomeFunction
或者使用别名:
from pandas import SomeFunction as SomeFunc
backtrader 提供了对 frompackages 指令的支持。让我们重新设计 MyIndicator:
class MyIndicator(bt.Indicator):
frompackages = (('pandas', 'SomeFunction'),)
lines = ('myline',)
params = (
('period', 50),
)
def next(self):
print('mylines[0]:', SomeFunction(self.lines.myline[0]))
当然,这开始增加更多的括号。例如,如果要从 pandas 中导入两个(2)个东西,看起来会像这样:
class MyIndicator(bt.Indicator):
frompackages = (('pandas', ['SomeFunction', 'SomeFunction2']),)
lines = ('myline',)
params = (
('period', 50),
)
def next(self):
print('mylines[0]:', SomeFunction2(SomeFunction(self.lines.myline[0])))
为了清晰起见,SomeFunction 和 SomeFunction2 已放在一个 list 而不是一个 tuple 中,以便使用方括号 [] 并更好地阅读它。
也可以将 SomeFunction 别名为例如 SFunc。完整示例:
class MyIndicator(bt.Indicator):
frompackages = (('pandas', [('SomeFunction', 'SFunc'), 'SomeFunction2']),)
lines = ('myline',)
params = (
('period', 50),
)
def next(self):
print('mylines[0]:', SomeFunction2(SFunc(self.lines.myline[0])))
从不同的包中导入也是可能的,但会增加更多的括号。当然,换行和缩进会有所帮助:
class MyIndicator(bt.Indicator):
frompackages = (
('pandas', [('SomeFunction', 'SFunc'), 'SomeFunction2']),
('statsmodel', 'XX'),
)
lines = ('myline',)
params = (
('period', 50),
)
def next(self):
print('mylines[0]:', XX(SomeFunction2(SFunc(self.lines.myline[0]))))
使用继承
packages 和 frompackages 都支持(多重)继承。例如,可以有一个基类,为所有子类添加 numpy 支持:
class NumPySupport(object):
packages = ('numpy',)
class MyIndicator(bt.Indicator, NumPySupport):
packages = ('pandas',)
MyIndicator 将需要从后台机制中导入 numpy 和 pandas 并将能够使用它们。
介绍 Kalman 和朋友
注意
下面的两个指标都需要同行审查以确认实现。谨慎使用。
下面可以找到一个实现 KalmanMovingAverage 的示例。这是模仿这里的一篇文章:Quantopian Lecture Series: Kalman Filters
实现:
class KalmanMovingAverage(bt.indicators.MovingAverageBase):
packages = ('pykalman',)
frompackages = (('pykalman', [('KalmanFilter', 'KF')]),)
lines = ('kma',)
alias = ('KMA',)
params = (
('initial_state_covariance', 1.0),
('observation_covariance', 1.0),
('transition_covariance', 0.05),
)
plotlines = dict(cov=dict(_plotskip=True))
def __init__(self):
self.addminperiod(self.p.period) # when to deliver values
self._dlast = self.data(-1) # get previous day value
def nextstart(self):
self._k1 = self._dlast[0]
self._c1 = self.p.initial_state_covariance
self._kf = pykalman.KalmanFilter(
transition_matrices=[1],
observation_matrices=[1],
observation_covariance=self.p.observation_covariance,
transition_covariance=self.p.transition_covariance,
initial_state_mean=self._k1,
initial_state_covariance=self._c1,
)
self.next()
def next(self):
k1, self._c1 = self._kf.filter_update(self._k1, self._c1, self.data[0])
self.lines.kma[0] = self._k1 = k1
还有一个基于这里的一篇文章的 KalmanFilter:Kalman Filter-Based Pairs Trading Strategy In QSTrader
class NumPy(object):
packages = (('numpy', 'np'),)
class KalmanFilterInd(bt.Indicator, NumPy):
_mindatas = 2 # needs at least 2 data feeds
packages = ('pandas',)
lines = ('et', 'sqrt_qt')
params = dict(
delta=1e-4,
vt=1e-3,
)
def __init__(self):
self.wt = self.p.delta / (1 - self.p.delta) * np.eye(2)
self.theta = np.zeros(2)
self.P = np.zeros((2, 2))
self.R = None
self.d1_prev = self.data1(-1) # data1 yesterday's price
def next(self):
F = np.asarray([self.data0[0], 1.0]).reshape((1, 2))
y = self.d1_prev[0]
if self.R is not None: # self.R starts as None, self.C set below
self.R = self.C + self.wt
else:
self.R = np.zeros((2, 2))
yhat = F.dot(self.theta)
et = y - yhat
# Q_t is the variance of the prediction of observations and hence
# \sqrt{Q_t} is the standard deviation of the predictions
Qt = F.dot(self.R).dot(F.T) + self.p.vt
sqrt_Qt = np.sqrt(Qt)
# The posterior value of the states \theta_t is distributed as a
# multivariate Gaussian with mean m_t and variance-covariance C_t
At = self.R.dot(F.T) / Qt
self.theta = self.theta + At.flatten() * et
self.C = self.R - At * F.dot(self.R)
# Fill the lines
self.lines.et[0] = et
self.lines.sqrt_qt[0] = sqrt_Qt
为了说明这一点,展示了 packages 如何与继承一起工作(pandas 实际上并不是必需的)
一个样例的执行:
$ ./kalman-things.py --plot
生成了这张图表
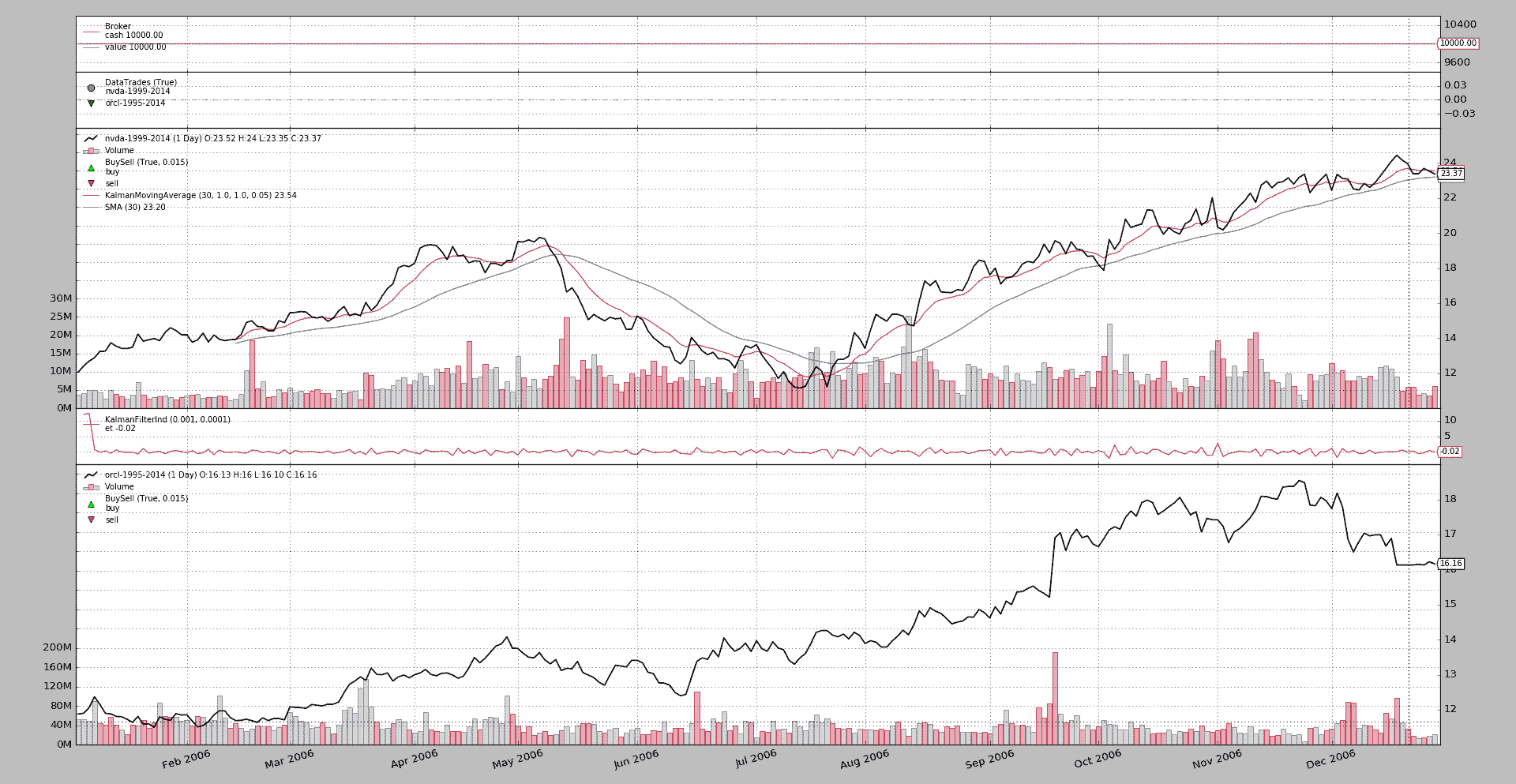
样例用法
$ ./kalman-things.py --help
usage: kalman-things.py [-h] [--data0 DATA0] [--data1 DATA1]
[--fromdate FROMDATE] [--todate TODATE]
[--cerebro kwargs] [--broker kwargs] [--sizer kwargs]
[--strat kwargs] [--plot [kwargs]]
Packages and Kalman
optional arguments:
-h, --help show this help message and exit
--data0 DATA0 Data to read in (default:
../../datas/nvda-1999-2014.txt)
--data1 DATA1 Data to read in (default:
../../datas/orcl-1995-2014.txt)
--fromdate FROMDATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default:
2006-01-01)
--todate TODATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default:
2007-01-01)
--cerebro kwargs kwargs in key=value format (default: runonce=False)
--broker kwargs kwargs in key=value format (default: )
--sizer kwargs kwargs in key=value format (default: )
--strat kwargs kwargs in key=value format (default: )
--plot [kwargs] kwargs in key=value format (default: )
样例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import backtrader as bt
class KalmanMovingAverage(bt.indicators.MovingAverageBase):
packages = ('pykalman',)
frompackages = (('pykalman', [('KalmanFilter', 'KF')]),)
lines = ('kma',)
alias = ('KMA',)
params = (
('initial_state_covariance', 1.0),
('observation_covariance', 1.0),
('transition_covariance', 0.05),
)
def __init__(self):
self.addminperiod(self.p.period) # when to deliver values
self._dlast = self.data(-1) # get previous day value
def nextstart(self):
self._k1 = self._dlast[0]
self._c1 = self.p.initial_state_covariance
self._kf = pykalman.KalmanFilter(
transition_matrices=[1],
observation_matrices=[1],
observation_covariance=self.p.observation_covariance,
transition_covariance=self.p.transition_covariance,
initial_state_mean=self._k1,
initial_state_covariance=self._c1,
)
self.next()
def next(self):
k1, self._c1 = self._kf.filter_update(self._k1, self._c1, self.data[0])
self.lines.kma[0] = self._k1 = k1
class NumPy(object):
packages = (('numpy', 'np'),)
class KalmanFilterInd(bt.Indicator, NumPy):
_mindatas = 2 # needs at least 2 data feeds
packages = ('pandas',)
lines = ('et', 'sqrt_qt')
params = dict(
delta=1e-4,
vt=1e-3,
)
def __init__(self):
self.wt = self.p.delta / (1 - self.p.delta) * np.eye(2)
self.theta = np.zeros(2)
self.R = None
self.d1_prev = self.data1(-1) # data1 yesterday's price
def next(self):
F = np.asarray([self.data0[0], 1.0]).reshape((1, 2))
y = self.d1_prev[0]
if self.R is not None: # self.R starts as None, self.C set below
self.R = self.C + self.wt
else:
self.R = np.zeros((2, 2))
yhat = F.dot(self.theta)
et = y - yhat
# Q_t is the variance of the prediction of observations and hence
# \sqrt{Q_t} is the standard deviation of the predictions
Qt = F.dot(self.R).dot(F.T) + self.p.vt
sqrt_Qt = np.sqrt(Qt)
# The posterior value of the states \theta_t is distributed as a
# multivariate Gaussian with mean m_t and variance-covariance C_t
At = self.R.dot(F.T) / Qt
self.theta = self.theta + At.flatten() * et
self.C = self.R - At * F.dot(self.R)
# Fill the lines
self.lines.et[0] = et
self.lines.sqrt_qt[0] = sqrt_Qt
class KalmanSignals(bt.Indicator):
_mindatas = 2 # needs at least 2 data feeds
lines = ('long', 'short',)
def __init__(self):
kf = KalmanFilterInd()
et, sqrt_qt = kf.lines.et, kf.lines.sqrt_qt
self.lines.long = et < -1.0 * sqrt_qt
# longexit is et > -1.0 * sqrt_qt ... the opposite of long
self.lines.short = et > sqrt_qt
# shortexit is et < sqrt_qt ... the opposite of short
class St(bt.Strategy):
params = dict(
ksigs=False, # attempt trading
period=30,
)
def __init__(self):
if self.p.ksigs:
self.ksig = KalmanSignals()
KalmanFilter()
KalmanMovingAverage(period=self.p.period)
bt.ind.SMA(period=self.p.period)
if True:
kf = KalmanFilterInd()
kf.plotlines.sqrt_qt._plotskip = True
def next(self):
if not self.p.ksigs:
return
size = self.position.size
if not size:
if self.ksig.long:
self.buy()
elif self.ksig.short:
self.sell()
elif size > 0:
if not self.ksig.long:
self.close()
elif not self.ksig.short: # implicit size < 0
self.close()
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
kwargs = dict()
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
for a, d in ((getattr(args, x), x) for x in ['fromdate', 'todate']):
if a:
strpfmt = dtfmt + tmfmt * ('T' in a)
kwargs[d] = datetime.datetime.strptime(a, strpfmt)
# Data feed
data0 = bt.feeds.YahooFinanceCSVData(dataname=args.data0, **kwargs)
cerebro.adddata(data0)
data1 = bt.feeds.YahooFinanceCSVData(dataname=args.data1, **kwargs)
data1.plotmaster = data0
cerebro.adddata(data1)
# Broker
cerebro.broker = bt.brokers.BackBroker(**eval('dict(' + args.broker + ')'))
# Sizer
cerebro.addsizer(bt.sizers.FixedSize, **eval('dict(' + args.sizer + ')'))
# Strategy
cerebro.addstrategy(St, **eval('dict(' + args.strat + ')'))
# Execute
cerebro.run(**eval('dict(' + args.cerebro + ')'))
if args.plot: # Plot if requested to
cerebro.plot(**eval('dict(' + args.plot + ')'))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=(
'Packages and Kalman'
)
)
parser.add_argument('--data0', default='../../datas/nvda-1999-2014.txt',
required=False, help='Data to read in')
parser.add_argument('--data1', default='../../datas/orcl-1995-2014.txt',
required=False, help='Data to read in')
# Defaults for dates
parser.add_argument('--fromdate', required=False, default='2006-01-01',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--todate', required=False, default='2007-01-01',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--cerebro', required=False, default='runonce=False',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--broker', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--sizer', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--strat', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--plot', required=False, default='',
nargs='?', const='{}',
metavar='kwargs', help='kwargs in key=value format')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()
百分位重加载
原文:
www.backtrader.com/blog/posts/2017-02-05-percentrank-reloaded/percentrank-reloaded/
社区用户@randyt已经能够将backtrader推至极限。找到一些晦涩的角落,甚至在那里添加了pdb语句,并且一直是获得重新取样流的更精细的同步的推动力。
最近,@randyt提交了一个拉取请求,集成了一个名为PercentRank的新指标。以下是原始代码
class PercentRank(bt.Indicator):
lines = ('pctrank',)
params = (('period', 50),)
def __init__(self):
self.addminperiod(self.p.period)
def next(self):
self.lines.pctrank[0] = \
(math.fsum([x < self.data[0]
for x in self.data.get(size=self.p.period)])
/ self.p.period)
super(PercentRank, self).__init__()
这真的展示了某人如何深入研究backtrader的源代码,提出了一些问题,并理解了一些概念。这真的很棒:
self.addminperiod(self.p.period)
出乎意料,因为最终用户甚至不会预期到某人可以在lines对象中使用该 API 调用。这个调用告诉机器确保指标至少有self.p.period个data feeds样本可用,因为它们需要用于计算。
在原始代码中可以看到self.data.get(size=self.p.period),这只有在后台引擎确保在进行第一次计算之前有那么多样本可用时才能起作用(如果使用exactbars来减少内存使用,则始终有那么多样本可用)
初始重载
代码可以重新编写以利用预先存在的旨在减轻开发的实用程序。没有什么最终用户必须知道的,但如果一个人不断开发或原型化指标,则是了解的好时机。
class PercentRank_PeriodN1(bt.ind.PeriodN):
lines = ('pctrank',)
params = (('period', 50),)
def next(self):
d0 = self.data[0] # avoid dict/array lookups each time
dx = self.data.get(size=self.p.period)
self.l.pctrank[0] = math.fsum((x < d0 for x in dx)) / self.p.period
重新使用PeriodN是关键,以消除self.addminperiod的魔术,并使指标在某种程度上更易处理。PeriodN已经具有一个period参数,并将为用户调用(如果__init__被覆盖,则记得调用super(cls, self).__init__())。
计算已被分解为 3 行,以首先缓存字典和数组查找,并使其更易读(尽管后者只是品味问题)
代码行数也从 13 减少到了 8 行。这通常在阅读时会有所帮助。
通过 OperationN 重载
像SumN这样的现有指标,它对数据源的值在一段时间内求和,不像上面那样直接构建在PeriodN上,而是构建在一个名为OperationN的子类上。与其父类一样,它仍然不定义lines,并且具有一个名为func的类属性。
func将被调用,其中包含宿主函数必须操作的期间的数据的数组。签名基本上是:func(data[0:period])并返回适合存储在line中的内容,即:一个浮点值。
知道了这一点,我们可以尝试一下显而易见的
class PercentRank_OperationN1(bt.ind.OperationN):
lines = ('pctrank',)
params = (('period', 50),)
func = (lambda d: math.fsum((x < d[-1] for x in d)) / self.p.period)
降至 4 行。但这将失败,只需要最后一行:
TypeError: <lambda>() takes 1 positional argument but 2 were given
(使用--strat n1=True使示例失败)
通过将我们的无名函数放入func中,似乎已将其转换为方法,因为它需要两个参数。这可以很快解决。
class PercentRank_OperationN2(bt.ind.OperationN):
lines = ('pctrank',)
params = (('period', 50),)
func = (lambda self, d: math.fsum((x < d[-1] for x in d)) / self.p.period)
它起作用了。但有一些不好看的地方:这不是大多数情况下人们期望传递函数的方式,即:将self作为参数。在这种情况下,我们控制函数,但这并不总是情况(可能需要一个包装器来解决)
在 Python 中的语法糖通过staticmethod拯救了我们,但在我们这样做之前,我们知道在staticmethod中将不再可能引用self.p.period,失去了以前进行平均计算的能力。
但由于func接收一个固定长度的可迭代对象,可以使用len。
现在是新代码。
class PercentRank_OperationN3(bt.ind.OperationN):
lines = ('pctrank',)
params = (('period', 50),)
func = staticmethod(lambda d: math.fsum((x < d[-1] for x in d)) / len(d))
一切都很好,但这让人思考为什么以前没有考虑让用户有机会传递自己的函数。子类化OperationN是一个不错的选择,但可能有更好的方法,避免使用staticmethod或将self作为参数并构建在backtrader中的机制之上。
让我们定义OperationN的一个方便的子类。
class ApplyN(bt.ind.OperationN):
lines = ('apply',)
params = (('func', None),)
def __init__(self):
self.func = self.p.func
super(ApplyN, self).__init__()
这应该很久以前就在平台上了。唯一真正需要考虑的是lines = ('apply',)是否必须存在,或者用户是否可以自由定义该行和其他一些行。在集成之前需要考虑的事情。
有了ApplyN,PercentRank的最终版本完全符合我们的所有预期。首先,手动平均计算版本。
class PercentRank_ApplyN(ApplyN):
params = (
('period', 50),
('func', lambda d: math.fsum((x < d[-1] for x in d)) / len(d)),
)
在不违反PEP-8的情况下,我们仍然可以重新格式化两者以适应 3 行… 很好!
让我们运行示例
下面可以看到的示例具有通常的骨架样板,但旨在展示不同PercentRank实现的视觉比较。
注意
使用--strat n1=True来执行它,尝试PercentRank_OperationN1版本,它不起作用
图形输出。
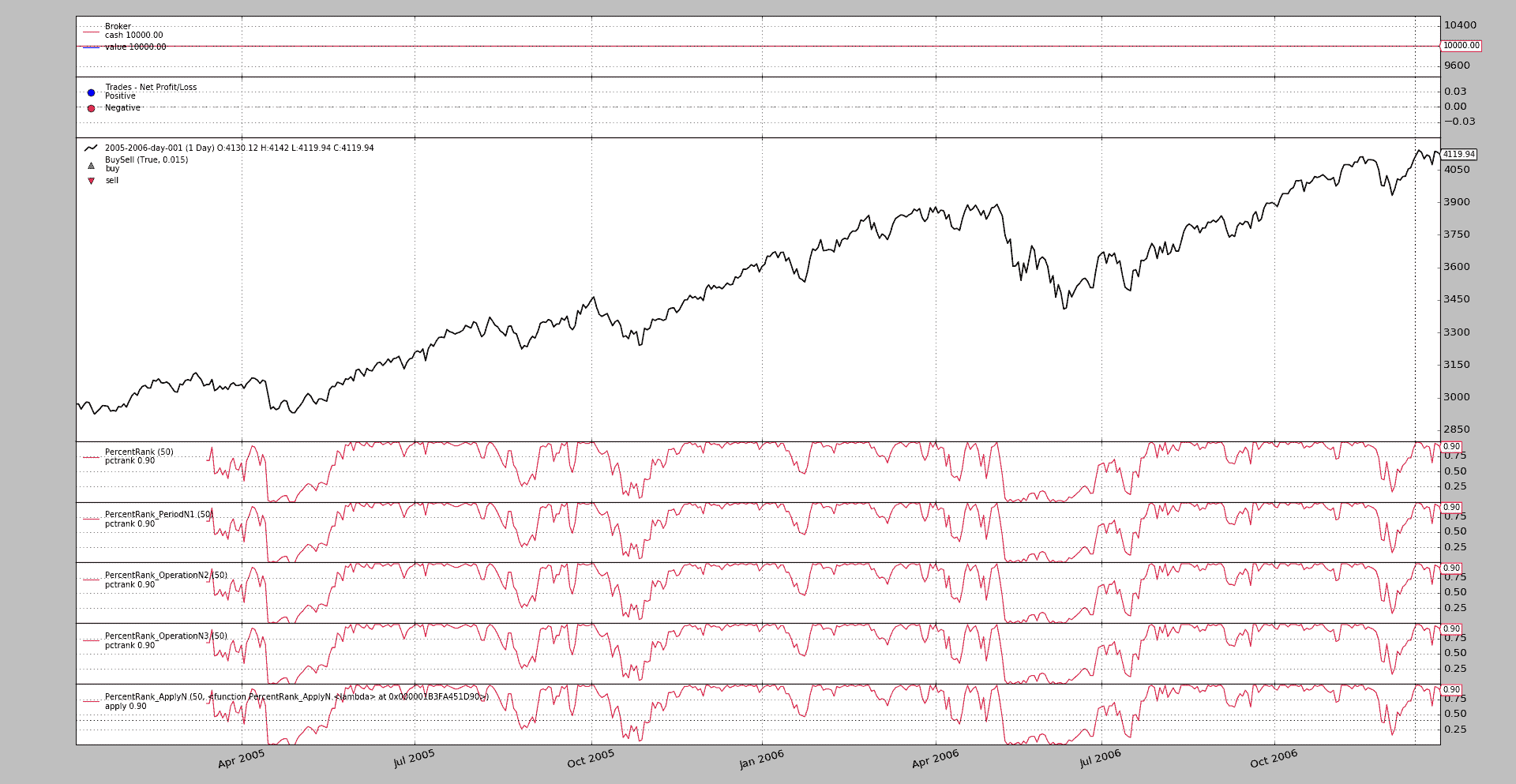
示例用法
$ ./percentrank.py --help
usage: percentrank.py [-h] [--data0 DATA0] [--fromdate FROMDATE]
[--todate TODATE] [--cerebro kwargs] [--broker kwargs]
[--sizer kwargs] [--strat kwargs] [--plot [kwargs]]
Sample Skeleton
optional arguments:
-h, --help show this help message and exit
--data0 DATA0 Data to read in (default:
../../datas/2005-2006-day-001.txt)
--fromdate FROMDATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default: )
--todate TODATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default: )
--cerebro kwargs kwargs in key=value format (default: )
--broker kwargs kwargs in key=value format (default: )
--sizer kwargs kwargs in key=value format (default: )
--strat kwargs kwargs in key=value format (default: )
--plot [kwargs] kwargs in key=value format (default: )
示例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import math
import backtrader as bt
class PercentRank(bt.Indicator):
lines = ('pctrank',)
params = (('period', 50),)
def __init__(self):
self.addminperiod(self.p.period)
def next(self):
self.lines.pctrank[0] = \
(math.fsum([x < self.data[0]
for x in self.data.get(size=self.p.period)])
/ self.p.period)
super(PercentRank, self).__init__()
class PercentRank_PeriodN1(bt.ind.PeriodN):
lines = ('pctrank',)
params = (('period', 50),)
def next(self):
d0 = self.data[0] # avoid dict/array lookups each time
dx = self.data.get(size=self.p.period)
self.l.pctrank[0] = math.fsum((x < d0 for x in dx)) / self.p.period
class PercentRank_OperationN1(bt.ind.OperationN):
lines = ('pctrank',)
params = (('period', 50),)
func = (lambda d: math.fsum((x < d[-1] for x in d)) / self.p.period)
class PercentRank_OperationN2(bt.ind.OperationN):
lines = ('pctrank',)
params = (('period', 50),)
func = (lambda self, d: math.fsum((x < d[-1] for x in d)) / self.p.period)
class PercentRank_OperationN3(bt.ind.OperationN):
lines = ('pctrank',)
params = (('period', 50),)
func = staticmethod(lambda d: math.fsum((x < d[-1] for x in d)) / len(d))
class ApplyN(bt.ind.OperationN):
lines = ('apply',)
params = (('func', None),)
def __init__(self):
self.func = self.p.func
super(ApplyN, self).__init__()
class PercentRank_ApplyN(ApplyN):
params = (
('period', 50),
('func', lambda d: math.fsum((x < d[-1] for x in d)) / len(d)),
)
class St(bt.Strategy):
params = (
('n1', False),
)
def __init__(self):
PercentRank()
PercentRank_PeriodN1()
if self.p.n1:
PercentRank_OperationN1()
PercentRank_OperationN2()
PercentRank_OperationN3()
PercentRank_ApplyN()
def next(self):
pass
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
kwargs = dict()
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
for a, d in ((getattr(args, x), x) for x in ['fromdate', 'todate']):
if a:
strpfmt = dtfmt + tmfmt * ('T' in a)
kwargs[d] = datetime.datetime.strptime(a, strpfmt)
# Data feed
data0 = bt.feeds.BacktraderCSVData(dataname=args.data0, **kwargs)
cerebro.adddata(data0)
# Broker
cerebro.broker = bt.brokers.BackBroker(**eval('dict(' + args.broker + ')'))
# Sizer
cerebro.addsizer(bt.sizers.FixedSize, **eval('dict(' + args.sizer + ')'))
# Strategy
cerebro.addstrategy(St, **eval('dict(' + args.strat + ')'))
# Execute
cerebro.run(**eval('dict(' + args.cerebro + ')'))
if args.plot: # Plot if requested to
cerebro.plot(**eval('dict(' + args.plot + ')'))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=(
'Sample Skeleton'
)
)
parser.add_argument('--data0', default='../../datas/2005-2006-day-001.txt',
required=False, help='Data to read in')
# Defaults for dates
parser.add_argument('--fromdate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--todate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--cerebro', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--broker', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--sizer', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--strat', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--plot', required=False, default='',
nargs='?', const='{}',
metavar='kwargs', help='kwargs in key=value format')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()
数字交叉
原文:
www.backtrader.com/blog/posts/2017-02-04-crossing-over-numbers/crossing-over-numbers/
在backtrader的1.9.27.105版本中已经纠正了一个疏忽。这是一个疏忽,因为所有的拼图都已经就位,但并没有在所有角落进行激活。
该机制使用一个名为_mindatas的属性,让我们称之为:mindatas。
社区提出了问题,答案并不完全正确。请查看这里的对话:
community.backtrader.com/topic/125/strategy-auto-generation/23
即使对话是关于其他事情的,问题也可以很快得到回答:“嘿,实际上应该可以工作!”但是现在谁有时间考虑一个恰当而周到的答案呢。
让我们考虑穿越一个普通的数字参数的用例。类似这样
mycrossover = bt.ind.CrossOver(bt.ind.RSI(), 50.0)
这将会像这样断开
Traceback (most recent call last):
File "./cross-over-num.py", line 114, in <module>
runstrat()
File "./cross-over-num.py", line 70, in runstrat
cerebro.run(**eval('dict(' + args.cerebro + ')'))
File "d:\dro\01-docs\01-home\src\backtrader\backtrader\cerebro.py", line 810, in run
runstrat = self.runstrategies(iterstrat)
File "d:\dro\01-docs\01-home\src\backtrader\backtrader\cerebro.py", line 878, in runstrategies
strat = stratcls(*sargs, **skwargs)
File "d:\dro\01-docs\01-home\src\backtrader\backtrader\metabase.py", line 87, in __call__
_obj, args, kwargs = cls.doinit(_obj, *args, **kwargs)
File "d:\dro\01-docs\01-home\src\backtrader\backtrader\metabase.py", line 77, in doinit
_obj.__init__(*args, **kwargs)
File "./cross-over-num.py", line 35, in __init__
bt.ind.CrossOver(bt.ind.RSI(), 50)
File "d:\dro\01-docs\01-home\src\backtrader\backtrader\indicator.py", line 53, in __call__
return super(MetaIndicator, cls).__call__(*args, **kwargs)
File "d:\dro\01-docs\01-home\src\backtrader\backtrader\metabase.py", line 87, in __call__
_obj, args, kwargs = cls.doinit(_obj, *args, **kwargs)
File "d:\dro\01-docs\01-home\src\backtrader\backtrader\metabase.py", line 77, in doinit
_obj.__init__(*args, **kwargs)
Typeerror: __init__() takes exactly 1 argument (2 given)
最后一行最具信息性,因为它告诉我们有太多的参数。这意味着50.0正在伤害我们。
为了解决手头的问题,给出了一个数字包装器作为答案。
class ConstantValue(bt.Indicator):
lines = ('constant',)
params = (('constant', float('NaN')),)
def next(self):
self.lines.constant[0] = self.p.constant
...
mycrossover = bt.ind.CrossOver(bt.ind.RSI(), ConstantValue(50.0))
问题解决了。但等等,解决方案已经在手边。有一个内部助手,用于解决问题,但被完全遗忘了:LineNum。它做的就是名字所暗示的:获取一个数字并将其变成一行。问题的解决方案就在那里,解决方案可能看起来像这样:
mycrossover = bt.ind.CrossOver(bt.ind.RSI(), bt.LineNum(50.0))
通常的后台线程仍在不断地运行,告诉我们仍然有一些地方不是 100%清晰,解决方案应该是显而易见的,而不需要用户指定包装器。
然后出现了疏忽。即使mindatas机制存在并应用于系统的某些部分,但并没有应用于CrossOver。尝试过,但有时人类会失败,他们相信自己已经做了某事,结果发现他们没有往下滚动。这就是情况。像这样添加一行代码:
class CrossOver(Indicator):
...
_mindatas = 2
...
现在问题的解决方案很明显:
mycrossover = bt.ind.CrossOver(bt.ind.RSI(), 50.0)
应该一直是这样的方式(参见下面的示例和图表)
mindatas在工作
这是一个方便的属性,旨在用于特定情况,因此前面有_,表示应该非常谨慎使用。指标的默认值是:
-
_mindatas = 1这告诉系统,如果没有向指标传递任何数据源,系统应该从父级复制第一个数据源。如果没有这个,例如实例化
RelativeStrengthIndicator应该这样做:class Strategy(bt.Indicator): def __init__(self): rsi = bt.ind.RSI(self.data0)`但是使用
_mindatas给出的默认指示,以下是可能的:class Strategy(bt.Indicator): def __init__(self): rsi = bt.ind.RSI()`结果完全相同,因为策略中的第一个数据源
self.data0被传递给RSI的实例化
像 CrossOver 这样的指示器需要 2 个数据源,因为它正在检查一件事是否穿过另一件事。在这种情况下,并如上所示,默认值已设置为:
_mindatas = 2
这告诉系统一些信息,比如:
-
如果没有数据被传递,则从父级复制 2 个数据源(如果可能的话)。
-
如果只传递了 1 个数据,尝试将下一个传入的参数转换为 lines 对象,以便有 2 个数据源可用。对于普通浮点数的线穿越用例很有用。再次参考:
mycrossover = bt.ind.CrossOver(bt.ind.RSI(), 50.0)` -
如果向
CrossOver传递了 2 个或更多个数据源,则不执行任何操作,并继续执行。
在社区中,最近已经将该机制应用于例如实现配对交易的 KalmanFilter 的第一稿。当谈论到配对时,需要 2 个数据源,因此:_mindatas = 2
一个小示例(尽管有一个完整的框架)来测试完整的解决方案:
$ ./cross-over-num.py --plot
这将产生这样的输出。
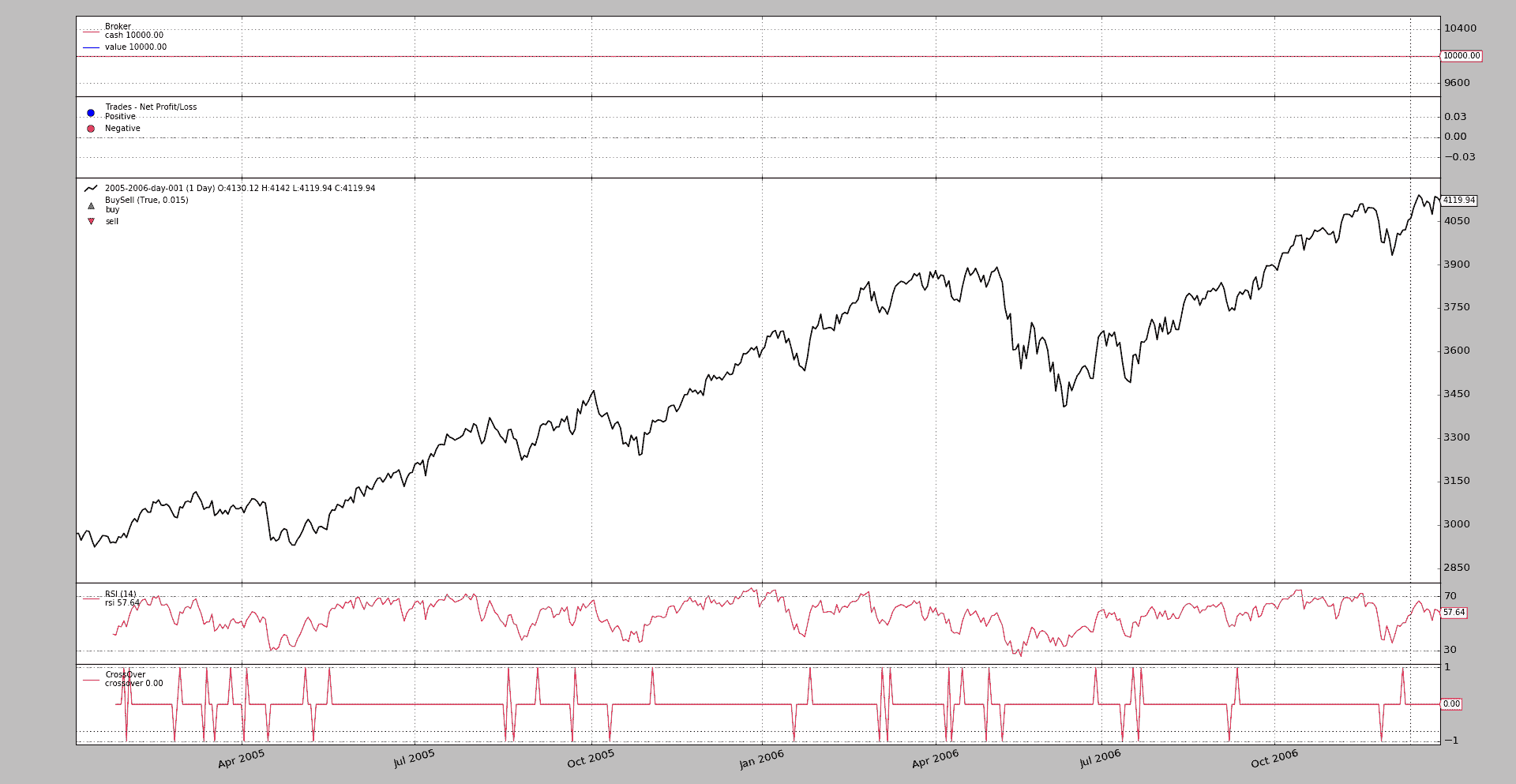
示例用法
$ ./cross-over-num.py --help
usage: cross-over-num.py [-h] [--data0 DATA0] [--fromdate FROMDATE]
[--todate TODATE] [--cerebro kwargs]
[--broker kwargs] [--sizer kwargs] [--strat kwargs]
[--plot [kwargs]]
Sample Skeleton
optional arguments:
-h, --help show this help message and exit
--data0 DATA0 Data to read in (default:
../../datas/2005-2006-day-001.txt)
--fromdate FROMDATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default: )
--todate TODATE Date[time] in YYYY-MM-DD[THH:MM:SS] format (default: )
--cerebro kwargs kwargs in key=value format (default: )
--broker kwargs kwargs in key=value format (default: )
--sizer kwargs kwargs in key=value format (default: )
--strat kwargs kwargs in key=value format (default: )
--plot [kwargs] kwargs in key=value format (default: )
示例代码
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import datetime
import backtrader as bt
class St(bt.Strategy):
params = ()
def __init__(self):
bt.ind.CrossOver(bt.ind.RSI(), 50)
def next(self):
pass
def runstrat(args=None):
args = parse_args(args)
cerebro = bt.Cerebro()
# Data feed kwargs
kwargs = dict()
# Parse from/to-date
dtfmt, tmfmt = '%Y-%m-%d', 'T%H:%M:%S'
for a, d in ((getattr(args, x), x) for x in ['fromdate', 'todate']):
if a:
strpfmt = dtfmt + tmfmt * ('T' in a)
kwargs[d] = datetime.datetime.strptime(a, strpfmt)
# Data feed
data0 = bt.feeds.BacktraderCSVData(dataname=args.data0, **kwargs)
cerebro.adddata(data0)
# Broker
cerebro.broker = bt.brokers.BackBroker(**eval('dict(' + args.broker + ')'))
# Sizer
cerebro.addsizer(bt.sizers.FixedSize, **eval('dict(' + args.sizer + ')'))
# Strategy
cerebro.addstrategy(St, **eval('dict(' + args.strat + ')'))
# Execute
cerebro.run(**eval('dict(' + args.cerebro + ')'))
if args.plot: # Plot if requested to
cerebro.plot(**eval('dict(' + args.plot + ')'))
def parse_args(pargs=None):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description=(
'Sample Skeleton'
)
)
parser.add_argument('--data0', default='../../datas/2005-2006-day-001.txt',
required=False, help='Data to read in')
# Defaults for dates
parser.add_argument('--fromdate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--todate', required=False, default='',
help='Date[time] in YYYY-MM-DD[THH:MM:SS] format')
parser.add_argument('--cerebro', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--broker', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--sizer', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--strat', required=False, default='',
metavar='kwargs', help='kwargs in key=value format')
parser.add_argument('--plot', required=False, default='',
nargs='?', const='{}',
metavar='kwargs', help='kwargs in key=value format')
return parser.parse_args(pargs)
if __name__ == '__main__':
runstrat()